7 Linking databases
Almost any empirical research project in accounting or finance research will involve merging data from multiple sources. When we joined data tables in Chapter 2, we had a common identifier across tables. But this will not always be the case. For example, to evaluate the market reaction to earnings announcements, we might start with data on comp.fundq from Compustat, where gvkey and datadate can be used to identify firm-quarters and associated announcement dates (rdq), and then look to merge with daily stock return data from the Center for Research in Security Prices (CRSP, pronounced “crisp”) on crsp.dsf, which uses permno and date to identify each firm’s trading equity and daily stock returns (ret). But this raises the question: Which permno (if any) matches a given gvkey?
Alternatively, given security price information from CRSP, we might want to know what is the most recent financial statement information for that security. In other words, which gvkey (if any) matches a given permno? This chapter provides guidance on the standard approaches to answering these questions with a focus on linking CRSP and Compustat.
The code in this chapter uses the packages listed below. For instructions on how to set up your computer to use the code found in this book, see Section 1.2. Quarto templates for the exercises below are available on GitHub.
7.1 Firm identifiers
The idea behind a firm identifier is that it uniquely identifies a firm for a particular purpose. While Compustat uses GVKEYs, CRSP uses PERMNOs, the SEC uses CIKs, stock exchanges use tickers, and there are also CUSIPs.1 Table 7.1 lists some common firm (and security) identifiers. Of course, identifiers apply not only to firms, but also people. Nonetheless, most of this chapter focuses on firm identifiers, in part because of the importance of firms as units of observation in accounting and finance research, and also because identifying firms is much harder than identifying people.2 While not specific to the platform we describe in this book, the issue of identifiers is one that seems less perplexing and better-handled when a relational database provides the backbone of your data store as it does here.
| Data provider | Firm identifiers | Notes |
|---|---|---|
Compustat (comp) |
gvkey |
|
CRSP (crsp) |
permno, permco
|
permno is a security identifier |
IBES (ibes) |
ticker |
ticker is not necessarily the ticker assigned to the firm by the exchange on which it trades |
| SEC EDGAR | CIK | |
Audit Analytics (audit) |
company_fkey |
company_fkey is the same as CIK |
| Various | CUSIP | CUSIP is a security identifier |
7.1.1 Firm identifiers: A quiz
Our sense is that firm identifiers is one of those topics that seem easy, but is actually fairly tricky. Here is a quick quiz to test your knowledge of firm identifiers.3
- General Motors Corporation declared bankruptcy in June 2009. Does the “successor firm” General Motors Company have the same GVKEY as General Motors Corporation? The same PERMNO?
- Can a CUSIP map to more than one PERMNO? To more than one GVKEY?
- Can a PERMNO map to more than one CUSIP?
- Can a GVKEY map to more than one PERMCO?
- Can a PERMCO map to different CIKs?
- If you have two data sets, \(X\) and \(Y\) and CUSIP is a “firm” identifier on each, can you simply merge using CUSIPs?
- When would a “firm” change CUSIPs?
- When would a “firm” change CIKs?
- If the firm identifier on IBES is
ticker, should I merge with CRSP usingtickerfromcrsp.stocknames?
Maybe you know the answers to some questions, but not all. If so, read on; this chapter aims to provide answers to many of these questions.4
7.2 The CRSP database
According to its website, “the Center for Research in Security Prices, LLC (CRSP) maintains the most comprehensive collection of security price, return, and volume data for the NYSE, AMEX and NASDAQ stock markets. Additional CRSP files provide stock indices, beta-based and cap-based portfolios, treasury bond and risk-free rates, mutual funds, and real estate data. [CRSP] maintains the most comprehensive collection of security price, return, and volume data for the NYSE, AMEX and NASDAQ stock markets. Additional CRSP files provide stock indices, beta-based and cap-based portfolios, treasury bond and risk-free rates, mutual funds, and real estate data.” We will discuss the CRSP/COMPUSTAT Merged Database in Section 7.3. CRSP documentation provides details on other CRSP databases, such as CRSP US Treasury and Inflation Series, CRSP Mutual Funds, and CRSP/Ziman Real Estate Data Series.
CRSP provides PERMNO, its own “permanent identifier” for each security in its database. Additionally, CRSP provides a company-level identifier, PERMCO, for each company. WRDS tells us that CRSP’s goals in creating these identifiers are to allow “for clean and accurate backtesting, time-series and event studies, measurement of performance, accurate benchmarking, and securities analysis.”
According to WRDS, “CRSP contains end-of-day and month-end prices on all listed NYSE, Amex, and NASDAQ common stocks along with basic market indices, and includes the most comprehensive distribution information available, with the most accurate total return calculations.” We create remote data frames for crsp.dsf (end-of-day prices) and crsp.msf (month-end prices).
db <- dbConnect(duckdb::duckdb())
dsf <- load_parquet(db, schema = "crsp", table = "dsf")
msf <- load_parquet(db, schema = "crsp", table = "msf")Let’s look at a few rows from crsp.dsf.
dsf |> collect(n = 5)# A tibble: 5 × 20
cusip permno permco issuno hexcd hsiccd date bidlo askhi prc
<chr> <int> <int> <int> <int> <int> <date> <dbl> <dbl> <dbl>
1 68391610 10000 7952 10396 3 3990 1986-01-07 2.38 2.75 -2.56
2 68391610 10000 7952 10396 3 3990 1986-01-08 2.38 2.62 -2.5
3 68391610 10000 7952 10396 3 3990 1986-01-09 2.38 2.62 -2.5
4 68391610 10000 7952 10396 3 3990 1986-01-10 2.38 2.62 -2.5
5 68391610 10000 7952 10396 3 3990 1986-01-13 2.5 2.75 -2.62
# ℹ 10 more variables: vol <dbl>, ret <dbl>, bid <dbl>, ask <dbl>,
# shrout <dbl>, cfacpr <dbl>, cfacshr <dbl>, openprc <dbl>,
# numtrd <int>, retx <dbl>The CRSP Indices database contains a number of CRSP indices. Here we focus on two index tables, crsp.dsi and crsp.msi, which can be viewed as complementing crsp.dsf and crsp.msf, respectively.
dsi <- load_parquet(db, schema = "crsp", table = "dsi")
msi <- load_parquet(db, schema = "crsp", table = "msi")7.2.1 Exercises
Looking at
crsp.dsfandcrsp.msf, we see thatprccan be negative. Do negative stock prices make sense economically? What do negative stock prices on CRSP mean?5 What would be an alternative approach to encode this information? (Write code to recast the data using this approach.) Why do you think that CRSP chose the approach it uses?How do
retandretxdiffer? Which variable are you more likely to use in research?Is the
datevariable oncrsp.msfalways the last day of the month? If not, why not?Suggest the “natural” primary key for
crsp.dsfandcrsp.msf. Check that this is a valid primary key forcrsp.msf.In the code below, we are using
collect()followed bymutate(month = floor_date(date, "month"))to calculatemonth. What changes occur in terms of where the processing happens if we replace these two lines withmutate(month = as.Date(floor_date("month", date))) |> collect()? Do we get different results? What effect doesas.Date()have?
- What is being depicted in Figures 7.1 and 7.2? What are the sources of variation across months in Figure 7.1? Can you guess what is the main driver of variation in Figure 7.2? Create an additional plot to visualize the source of variation in Figure 7.1 not depicted in Figure 7.2.
plot_data |>
count(month) |>
ggplot(aes(x = month, y = n)) +
geom_bar(stat = "identity") +
scale_x_date(date_breaks = "2 months", expand = expansion()) +
theme(axis.text.x = element_text(angle = 90))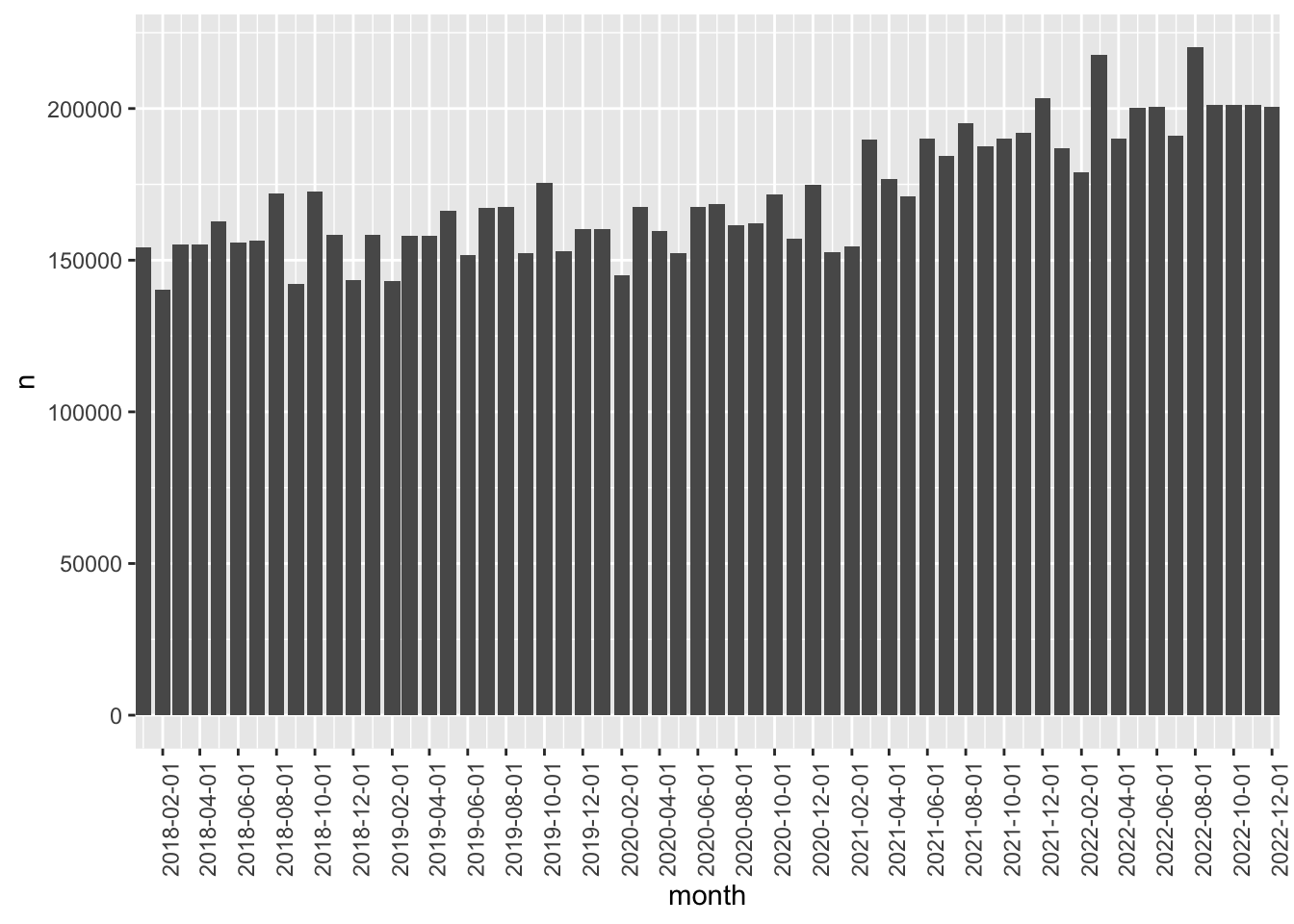
plot_data |>
distinct() |>
count(month) |>
ggplot(aes(x = month, y = n)) +
geom_bar(stat = "identity") +
scale_x_date(date_breaks = "2 months", expand = expansion()) +
theme(axis.text.x = element_text(angle = 90))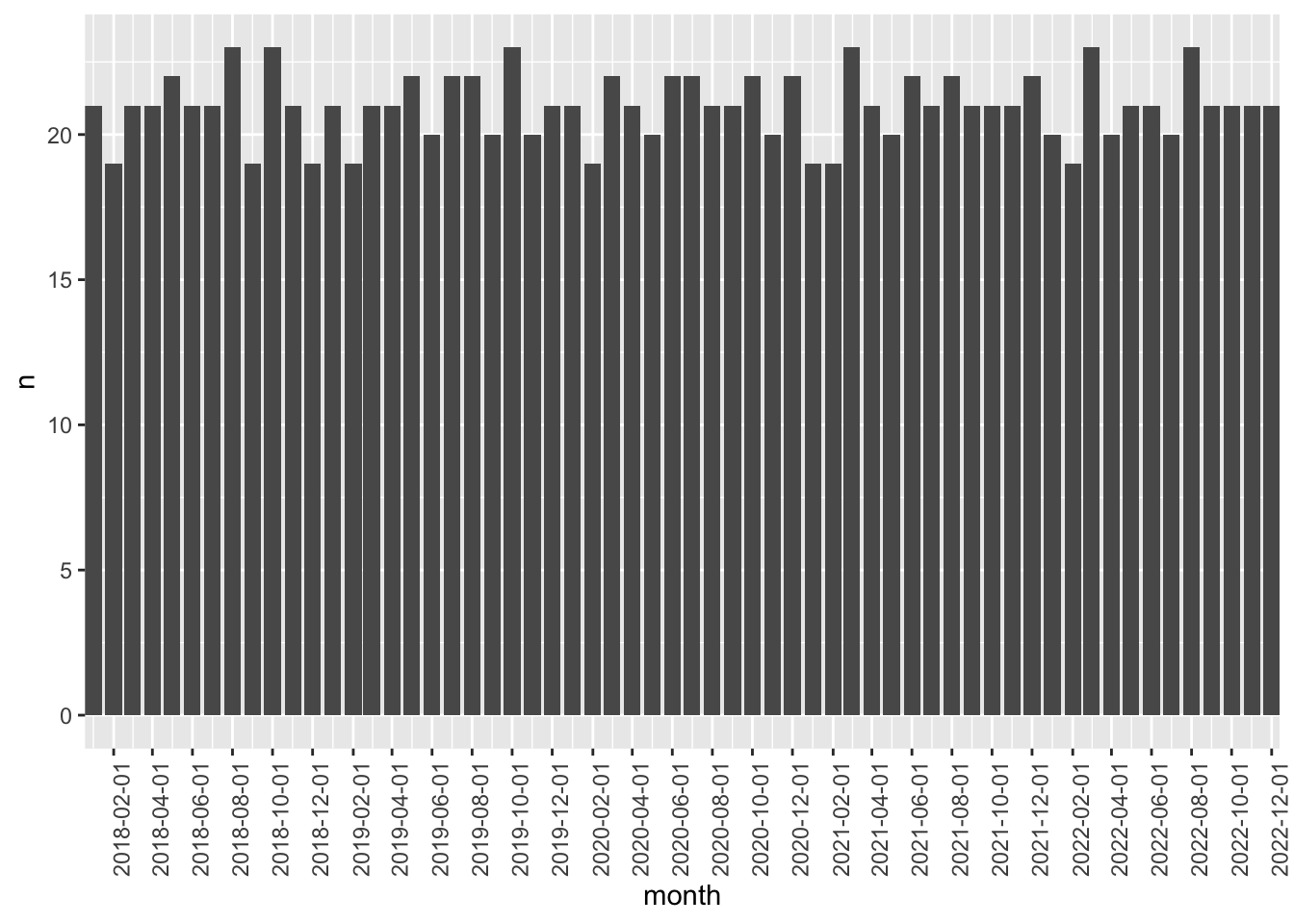
What is the primary key for
crsp.dsiandcrsp.msi? Verify that it is a valid key for both tables.Using the
dplyrverbanti_join(), determine if there are any dates oncrsp.dsfthat do not appear oncrsp.dsior vice versa. Do the same forcrsp.msiandcrsp.msf.
7.3 Linking CRSP and Compustat
The CRSP/Compustat Merged (CCM) database provides the standard link between CRSP data and Compustat’s fundamental data. The CCM provides three tables that you will see in common use:
crsp.ccmxpf_lnkhistcrsp.ccmxpf_lnkusedcrsp.ccmxpf_linktable
The reality is that the only table we need to worry about is crsp.ccmxpf_lnkhist, as the other two tables can be (and likely are) constructed from it (see here for details).6
ccmxpf_lnkhist <- load_parquet(db, schema = "crsp", table = "ccmxpf_lnkhist")7.3.1 Building a link table
In this section, we work towards creating a link table that can be used in subsequent chapters and that represents what appears to the standard approach in research.
The basic idea of crsp.ccmxpf_lnkhist one can match a gvkey-date combination to a PERMNO (here called lpermno) by merging on gvkey where the date is between linkdt and linkenddt. A few rows from crsp.ccmxpf_lnkhist are shown in Table 7.2. We can see in Table 7.2 that there are cases where lpermno is NA, so “matching” these rows will result in non-matches, which would seem to have no real value.
ccmxpf_lnkhist |>
collect(n = 10)crsp.ccmxpf_lnkhist
| gvkey | linkprim | liid | linktype | lpermno | lpermco | linkdt | linkenddt |
|---|---|---|---|---|---|---|---|
| 001000 | C | 00X | NU | NA | NA | 1961-01-01 | 1970-09-29 |
| 001000 | P | 01 | NU | NA | NA | 1970-09-30 | 1970-11-12 |
| 001000 | P | 01 | LU | 25881 | 23369 | 1970-11-13 | 1978-06-30 |
| 001001 | C | 00X | NU | NA | NA | 1978-01-01 | 1983-09-19 |
| 001001 | P | 01 | LU | 10015 | 6398 | 1983-09-20 | 1986-07-31 |
| 001002 | C | 00X | NR | NA | NA | 1960-01-01 | 1970-09-29 |
| 001002 | C | 01 | NR | NA | NA | 1970-09-30 | 1972-12-13 |
| 001002 | C | 01 | NR | NA | NA | 1973-06-06 | 1973-08-31 |
| 001002 | C | 01 | LC | 10023 | 22159 | 1972-12-14 | 1973-06-05 |
| 001003 | C | 00X | NU | NA | NA | 1980-01-01 | 1983-12-06 |
The only value of these non-matches might be data on their linktype. Table 7.3 provides the distribution of linktype in crsp.ccmxpf_lnkhist. If a non-match has linktype of NR, then the lack of a link has been “confirmed by research” (presumably by CRSP). If it has linktype of NU, the lack of link is “not yet confirmed” by research, so a diligent researcher might want to investigate.7
ccmxpf_lnkhist |>
mutate(has_permno = !is.na(lpermno)) |>
count(has_permno, linktype) |>
arrange(has_permno, desc(n))linktype in crsp.ccmxpf_lnkhist
| has_permno | linktype | n |
|---|---|---|
| FALSE | NR | 43255 |
| FALSE | NU | 34125 |
| FALSE | NP | 4 |
| TRUE | LC | 17013 |
| TRUE | LU | 15993 |
| TRUE | LS | 5158 |
So, in practice, we would likely ignore all matches with linktype %in% c("NU", "NR", "NP") or (equivalently) is.na(lpermno).
The cases where linktype is LD represent cases where two GVKEYs map to a single PERMNO at the same time and, according to WRDS, “this link should not be used.” Table 7.4 provides an example.
ccmxpf_lnkhist |> filter(lpermno == 23536)| gvkey | linkprim | liid | linktype | lpermno | lpermco | linkdt | linkenddt |
|---|---|---|---|---|---|---|---|
| 011550 | P | 01 | LC | 23536 | 21931 | 1962-01-31 | NA |
| 013353 | P | 01 | LD | 23536 | 21931 | 1962-01-31 | 1986-12-31 |
| 013353 | C | 99X | LD | 23536 | 21931 | 1987-01-01 | 2020-12-31 |
Here we’ll take the WRDS’s advice and omit these.
The cases where linktype is LX are ones where the Compustat security trades on a foreign exchange (so is not covered by CRSP) and CRSP is merely “helpfully” linking to a different security that is found on CRSP. Table 7.5 provides an example.
linktype is LX
| gvkey | linkprim | liid | linktype | lpermno | lpermco | linkdt | linkenddt |
|---|---|---|---|---|---|---|---|
| 001186 | P | 01 | LC | 78223 | 26174 | 1982-11-01 | NA |
| 001186 | N | 01C | LX | 78223 | 26174 | 1982-11-01 | NA |
These matches are duplicates and we don’t want them.
The remaining category for discussion is where linktype is LN. These are cases where a link exists, but Compustat does not have price data to allow CRSP to check the quality of the link. While researcher discretion might be used to include these, most researchers appear to exclude these cases and we will do likewise. Given the above, we only include cases where linktype is in LC (valid, researched link), LU (unresearched link), or LS (link valid for this lpermno only).
We now consider linkprim, which WRDS explains as follows:
linkprimclarifies the link’s relationship to Compustat’s marked primary security within the related range. “P” indicates a primary link marker, as identified by Compustat in monthly security data. “C” indicates a primary link marker, as identified by CRSP to resolve ranges of overlapping or missing primary markers from Compustat in order to produce one primary security throughout the company history. “J” indicates a joiner secondary issue of a company, identified by Compustat in monthly security data.
This suggests we should omit cases where linkprim equals J. Given that cases where linkprim equals N are duplicated links due to the existence of Canadian securities for a US-traded firm, we will exclude these too.
Table 7.6 provides data on linkprim for valid links.
linkprim for valid links
| linkprim | n |
|---|---|
| P | 29689 |
| C | 7961 |
| J | 420 |
| N | 94 |
Based on this, we focus on cases where linkprim is either C or P.
A final consideration is the presence of missing values on linkenddt. In general, these missing values indicate that the link remains valid at the time the data set was constructed. One approach would be to filter using code something like datadate <= linkenddt | is.na(linkenddt). Another approach would be to fill in missing values with a date that represents the plausible latest date for the data set. We take the latter approach in the code we use to create our final iteration of ccm_link.
A natural question is whether, for any given gvkey, there is only one PERMNO that is matched with linkprim IN ('P', 'C') on any given date. We can examine this by looking for overlapping date ranges between different rows of ccm_link for a given gvkey. The date range for each row starts with linkdt and ends with linkenddt. Ordering the rows by linkdt, there is overlap between the current row and the next row if the current row’s date range ends after the start of the next row’s date range.
For this purpose, we use two window functions: lag() and lead(). These are called window functions because each operates on a “window” of data.8 Here each window comprises data for a single gvkey ordered by linkdt. For each row within a window, we look at the previous row (if any) to get lag(linkenddt) and the following row (if any) to get lead(linkdt). The following code counts the number of overlapping rows.
ccm_link |>
group_by(gvkey) |>
window_order(linkdt) |>
mutate(lag_linkenddt = lag(linkenddt),
lead_linkdt = lead(linkdt),) |>
filter(lag_linkenddt >= linkdt | linkenddt >= lead_linkdt) |>
ungroup() |>
count() |>
pull()[1] 0So, there are no cases of overlapping dates, which confirms that only one lpermno is linked to a given gvkey for a given date. As can be seen in Table 7.7, the vast majority of GVKEYs map to just one PERMNO even without regard to date.
ccm_link |>
group_by(gvkey) |>
summarize(num_permnos = n_distinct(lpermno)) |>
count(num_permnos, sort = TRUE)| num_permnos | n |
|---|---|
| 1 | 32198 |
| 2 | 1056 |
| 3 | 76 |
| 4 | 3 |
| 5 | 1 |
The case with 5 PERMNOs is a complicated one involving tracking stock, spin-offs, etc.9 But one observation doesn’t matter much.
Our sense is that the last iteration of ccm_link above is more or less the standard approach used by researchers in practice and it’s the one we use in the rest of this book. While you may occasionally see code that filters on usedflag == 1, which is a variable found on crsp.ccmxpf_lnkused, not on crsp.ccmxpf_lnkhist, it can be shown that this yields exactly the same result as ccm_link above.
7.3.2 Applying the link table
This section provides an analysis of our link table ccm_link with a focus on cases where the linked PERMNO changes between the datadate associated with the financial statements and the date when earnings were announced (rdq). We get datadate for fiscal years from comp.funda and rdq comes from comp.fundq and we start by creating remote data tables for these sources.
funda <- load_parquet(db, schema = "comp", table = "funda")
fundq <- load_parquet(db, schema = "comp", table = "fundq")The following code generates from Compustat the table of events that we can link to CRSP. We start with the fourth-quarter data for “report date of quarterly earnings”, which is the variable rdq on comp.fundq.
We then link with (gvkey, datadate) combinations from comp.funda and focus on fiscal years ending on or after 1 January 2000.
funda_mod <-
funda |>
filter(indfmt == "INDL", datafmt == "STD",
consol == "C", popsrc == "D")
annc_dates <-
funda_mod |>
select(gvkey, datadate) |>
inner_join(rdqs, by = c("gvkey", "datadate")) |>
filter(datadate >= "2000-01-01")The resulting table has gvkey and datadate, as well as rdq. But in linking to CRSP, a question arises as to which date to use to check that a link is valid at the relevant time. This question seems difficult to answer in the abstract, so let’s try both dates (datadate and rdq) and drill deeper into cases where the linked permno values differ (when the linked permno is the same, we are probably safe).
We first merge with ccm_link using datadate to create datadate_permnos.
datadate_permnos <-
annc_dates |>
inner_join(ccm_link,
by = join_by(gvkey,
between(datadate, linkdt, linkenddt))) |>
select(gvkey, datadate, rdq, lpermno, lpermco) |>
rename(permno = lpermno,
permco = lpermco)We then merge with ccm_link using rdq to create rdq_permnos.
rdq_permnos <-
annc_dates |>
inner_join(ccm_link,
join_by(gvkey, between(rdq, linkdt, linkenddt))) |>
select(gvkey, datadate, rdq, lpermno, lpermco) |>
rename(permno = lpermno,
permco = lpermco) The table link_table_combined computes a full_join() of rdq_permnos and datadate_permnos and then compares matches across the alternative test dates.
link_table_combined <-
rdq_permnos |>
full_join(datadate_permnos,
by = c("gvkey", "datadate", "rdq"),
suffix = c("_rdq", "_ddate")) |>
filter(!is.na(permno_rdq) | !is.na(permno_ddate)) |>
mutate(same_permno = coalesce(permno_rdq == permno_ddate, FALSE),
same_permco = coalesce(permco_rdq == permco_ddate, FALSE),
has_permno_rdq = !is.na(permno_rdq),
has_permno_ddate = !is.na(permno_ddate)) Analysis of the data in link_table_combined is provided in Table 7.8.
link_table_stats <-
link_table_combined |>
count(same_permno, same_permco,
has_permno_rdq, has_permno_ddate) |>
arrange(same_permno, same_permco,
has_permno_rdq, has_permno_ddate) |>
ungroup() |>
arrange(desc(n))
link_table_statsdatadate versus rdq
| same_permno | same_permco | has_permno_rdq | has_permno_ddate | n |
|---|---|---|---|---|
| TRUE | TRUE | TRUE | TRUE | 124673 |
| FALSE | FALSE | FALSE | TRUE | 4577 |
| FALSE | FALSE | TRUE | FALSE | 3059 |
| FALSE | FALSE | TRUE | TRUE | 24 |
| FALSE | TRUE | TRUE | TRUE | 22 |
So in 124,673 (94.2%) cases, we match to the same permno using either date. In many cases, we match to a permno using one date but not the other. In 3059 cases, we have a permno link on rdq, but not on datadate. Inspecting some of these cases, they appear to be cases where the stock was not traded on datadate, but was trading by rdq, perhaps due to an IPO in the meantime.
In 4577 cases, we have a permno link on datadate, but not on rdq. One example is the gvkey of 021998, which on 2017-12-31 relates to the firm Neothetics Inc. According to a 10-K filing, “on January 17, 2018, Neothetics, Inc., or Neothetics, and privately-held Evofem Biosciences Operations, Inc., or Private Evofem, completed … the Merger. … The Merger was structured as a reverse capitalization and Private Evofem was determined to be the accounting acquirer based on the terms of the Merger and other factors.” So the continuing entity with respect to financial reporting is Evofem, which has a GVKEY of 032961.
The twist in this case is that “the financial information included in the first 10-K filed after the merger is that of Neothetics prior to the Merger.” Thus, the representation of ni and at as continuous series up to 2017-12-31 provided by Compustat for gvkey of 021998 (see below) and a series starting from 2018-12-31 for gvkey of 032961 seems correct. Inspection of the financial statements for the period ending 2018-12-31 suggests that there are values that could be supplied for gvkey of 032961 and datadate of 2017-12-31 (Compustat leaves these missing). However, it seems inappropriate to view the market reaction on rdq (2018-02-26) as being to the financial statement information associated with either gvkey (021998 or 032961) alone and thus a non-match on ccm_link seems appropriate.
ccm_link |>
filter(lpermno == 15075)| gvkey | linkprim | liid | linktype | lpermno | lpermco | linkdt | linkenddt |
|---|---|---|---|---|---|---|---|
| 021998 | P | 01 | LC | 15075 | 55117 | 2014-11-20 | 2018-01-17 |
| 032961 | P | 01 | LC | 15075 | 55117 | 2018-01-18 | 2022-08-10 |
ccm_link |>
filter(lpermno == 15075) |>
select(gvkey) |>
inner_join(funda_mod, by = "gvkey") |>
select(gvkey, datadate, at, ni) |>
arrange(datadate)| gvkey | datadate | at | ni |
|---|---|---|---|
| 021998 | 2012-12-31 | 12.82 | -7.83 |
| 021998 | 2013-12-31 | 4.53 | -15.02 |
| 021998 | 2014-12-31 | 76.90 | -10.82 |
| 021998 | 2015-12-31 | 40.11 | -43.16 |
| 021998 | 2016-12-31 | 12.82 | -13.02 |
| 021998 | 2017-12-31 | 4.12 | -9.99 |
Only in 46 cases do we find different permno values on the two dates. In 22 cases, we link to different permno values, but the same permco value. One of these cases is for gvkey of 017010. It’s not clear why CRSP switched the primary permno on 2018-01-01.10
| gvkey | linkprim | liid | linktype | lpermno | lpermco | linkdt | linkenddt |
|---|---|---|---|---|---|---|---|
| 017010 | P | 01 | LC | 15998 | 54311 | 2016-04-18 | 2017-12-31 |
| 017010 | J | 01 | LC | 15998 | 54311 | 2018-01-01 | NA |
| 017010 | J | 03 | LC | 16000 | 54311 | 2016-04-18 | 2017-12-31 |
| 017010 | P | 03 | LC | 16000 | 54311 | 2018-01-01 | NA |
What about the 24 cases with different permco values? Looking at the case where gvkey is 183603, the issue is a merger. According to the 10-K filed by Colony Northstar Inc. on 2017-02-28, “on January 10, 2017, NSAM completed the tri-party merger with Colony Capital, Inc., or Colony, and NorthStar Realty Finance Corp., or NorthStar Realty or NRF, under which the companies combined in an all-stock merger of equals transaction, referred to as the Mergers, to create Colony NorthStar, an internally-managed, diversified real estate and investment management company. … Although NSAM is the legal acquirer in the Mergers, Colony has been designated as the accounting acquirer, resulting in a reverse acquisition of NSAM for accounting purposes.” The issue here is that the gvkey of 183603, which related to Colony prior to the merger, survives on Compustat, while the permno of 14686, which related to NSAM prior to the merger, is the surviving permno. The correct approach here depends to some extent on the research question. As the net income reported on 2017-02-28 relates to an entity (a pre-merger Colony) whose securities ceased to trade on 2017-01-10, the correct answer seems to be that there is no appropriate permno to use for measuring the market reaction to earnings on 2017-02-28.
In summary, it appears that observations that have a permno link on datadate, but not on rdq, or whose matched permno changes between these two dates are problematic and should not be used for our hypothetical event study. Observations with a permno link on rdq but not on datadate seem more appropriate, but are likely to be new firms in some way.
7.4 All about CUSIPs
According to CUSIP Global Services, “CUSIP identifiers are the universally accepted standard for classifying financial instruments across institutions and exchanges worldwide. Derived from the Committee on Uniform Security Identification Procedures, CUSIPs are nine-character identifiers that capture an issue’s important differentiating characteristics for issuers and their financial instruments in the U.S. and Canada.”
CUSIP Global Services uses the CUSIP of Amazon.com’s common stock, 023135106, as an example of the components of a nine-character CUSIP. The first six characters—023135—represent the issuer, which is Amazon.com. While in this case the issuer is a company, an issuer could be a municipality or a government agency. The next two characters (10) indicate the type of instrument (e.g., debt or equity) and also uniquely identifies the issue among the issuer’s securities. The final character (6) is a check digit created by a mathematical formula. This last character will indicate any corruption of the preceding eight characters. Note that the characters need not be digits. For example, according to an SEC filing, the Class C Common Stock of Dell Technologies Inc. has a CUSIP of 24703L202, which contains the letter L.
While a full CUSIP always comprises nine characters, many data services abbreviate the CUSIP by omitting the check digit (to create an “eight-digit” CUSIP) or both the check digit and the issue identifier (to create a “six-digit” CUSIP). For example, the CRSP table crsp.stocknames uses eight-digit CUSIPs.
Notwithstanding the existence of crsp.ccmxpf_lnkhist, some researchers choose to link CRSP and Compustat using CUSIPs. For example, the code supplied with Jame et al. (2016) merges CRSP daily data on returns, prices, volume, and shares outstanding with Compustat data on shareholders’ equity using CUSIP and “year”.11
To evaluate the appropriateness of using CUSIPs to link CRSP and Compustat, we can construct a link table for comp.funda using CUSIPs (funda_cusip_link below) and compare it with an analogous link table constructed using ccm_link (funda_ccm_link below). First, let’s construct the subset of comp.funda of interest.
Our source for PERMNO-CUSIP links is crsp.stocknames. There are some cases where there is no value on ncusip, but there is a value on cusip and we use coalesce() to fill in missing values in such cases.
stocknames <- load_parquet(db, schema = "crsp", table = "stocknames")Now we can construct funda_cusip_link containing CUSIP-based matches for each (gkvey, datadate).
funda_cusip_link <-
funda_mod |>
mutate(ncusip = str_sub(cusip, 1L, 8L)) |>
inner_join(stocknames_plus,
join_by(ncusip,
between(datadate, namedt, nameenddt))) |>
select(gvkey, datadate, permno, permco)Similarly, we can construct our matches using ccm_link.
Finally, we combine both sets of matches in funda_link_combined for comparison.
funda_link_combined <-
funda_mod |>
select(-cusip) |>
left_join(funda_ccm_link, by = join_by(gvkey, datadate)) |>
left_join(funda_cusip_link,
by = join_by(gvkey, datadate),
suffix = c("_ccm", "_cusip")) |>
mutate(same_permno = permno_ccm == permno_cusip,
same_permco = permco_ccm == permco_cusip,
has_permno_ccm = !is.na(permno_ccm),
has_permno_cusip = !is.na(permno_cusip)) |>
filter(has_permno_ccm | has_permno_cusip) |>
collect()Regarding Table 7.9, we can probably view the cases with same_permno as valid matches, but would probably need to check the cases where same_permno is FALSE.
funda_link_combined |>
count(same_permno, same_permco)| same_permno | same_permco | n |
|---|---|---|
| FALSE | FALSE | 131 |
| FALSE | TRUE | 160 |
| TRUE | TRUE | 242840 |
| NA | NA | 118522 |
The cases where same_permno is NA in Table 7.9 are explored in Table 7.10. We would need to investigate the cases where one of permno_ccm or permno_cusip is NA to understand the source of the non-matches in one table or the other. However, a reasonable view seems to be that ccm_link provides many valid matches that are lost when matching using CUSIPs and for this reason crsp.ccmxpf_lnkhist should be preferred to CUSIP-based matches.
funda_link_combined |>
count(has_permno_ccm, has_permno_cusip)| has_permno_ccm | has_permno_cusip | n |
|---|---|---|
| FALSE | TRUE | 3233 |
| TRUE | FALSE | 115289 |
| TRUE | TRUE | 243131 |
7.4.1 Exercises
Is there any evidence of “reuse” of CUSIPs on
crsp.stocknames? In other words, are there anyncusiporcusipvalues associated with more than onepermno?The CRSP table
crsp.stocknamesincludes two CUSIP-related fields,cusipandncusip. What are the differences between the two fields? What does it mean whenncusipis missing, butcusipis present?Like CUSIPs, PERMNOs are security-level identifiers. Can a PERMNO be associated with more than one CUSIP at a given point in time? Can a PERMNO be associated with more than one CUSIP over time?
Looking at entries on
crsp.stocknameswheretickerisDELL, we see two differentpermnovalues. What explains this?
stocknames |>
filter(str_detect(comnam, '^DELL ')) |>
select(permno, cusip, ncusip, comnam, siccd, namedt, nameenddt)| permno | cusip | ncusip | comnam | siccd | namedt | nameenddt |
|---|---|---|---|---|---|---|
| 11081 | 24702R10 | 24702510 | DELL COMPUTER CORP | 3570 | 1988-06-22 | 2003-07-21 |
| 11081 | 24702R10 | 24702R10 | DELL INC | 3570 | 2003-07-22 | 2013-10-29 |
| 16267 | 24703L10 | 24703L10 | DELL TECHNOLOGIES INC | 3824 | 2016-09-07 | 2018-12-27 |
| 18267 | 24703L20 | 24703L20 | DELL TECHNOLOGIES INC | 3824 | 2018-12-28 | 2020-03-22 |
| 18267 | 24703L20 | 24703L20 | DELL TECHNOLOGIES INC | 3571 | 2020-03-23 | 2023-12-29 |
Looking at
permnoof11081(Dell), we see two different CUSIP values. What change appears to have caused the change in CUSIP for what CRSP regards as the same security?Choose a row from
funda_link_combinedwheresame_permcoisFALSE. Can you discern from the underlying tables what issue is causing the difference and which match (if any) is valid? (Hint: Do rows wheregvkey %in% c("065228", "136265")meet this condition? What appears to be the issue for these GVKEYs?) Can you conclude that the CCM-based match is the preferred one in each case?Choose a row from
funda_link_combinedwherehas_permno_cusipisTRUEandhas_permno_ccmisFALSE. Can you discern from the underlying tables whether the CUSIP-based match is valid? (Hint: Do rows wheregvkey %in% c("033728", "346027")meet this condition? What appears to be the issue for these GVKEYs?)Given the results shown in Tables 7.9 and 7.10 and your answer to the previous two questions, can you conclude that the CCM-based match is preferred to the CUSIP-based match in each case?
Of course, PERMNOs, CUSIPs, and tickers (at best) identify securities, not firms. More on this below.↩︎
In the United States, a Social Security Number (SSN) is a pretty robust identifier of people, as would be a Tax File Number (TFN) in Australia. Though, as researchers, we generally don’t have access to SSNs or TFNs.↩︎
Obviously, we are assuming that you recognize the various identifiers. If not, read on.↩︎
Coverage of CIKs is deferred to Chapter 23 and we do not use IBES data in this book.↩︎
CRSP documentation can be found at https://go.unimelb.edu.au/gcd8.↩︎
WRDS says “SAS programmers should use the Link History dataset (
ccmxpf_lnkhist) from CRSP”: https://go.unimelb.edu.au/akw8.↩︎The meaning of a
linktypeofNPis unclear, as no documentation of this code seems to exist.↩︎A careful reader might have noticed that we actually already use a window function in Chapter 2, namely
fill(). However, there we usedarrange()instead ofwindow_order(). Thewindow_order()function is only available for remote data frames because it provides functionality not available with local data frames. Readers coming from an SQL background might observe thatdplyr’sgroup_by()is “overloaded” in the sense that it does the work of both theGROUP BYstatement and thePARTITION BYclause in SQL. A short discussion of window functions is found in Chapter 21 of R for Data Science.↩︎See https://go.unimelb.edu.au/z9w8 for details.↩︎
The same seems to be true for the case with
gvkeyof003581. Again, it’s not clear why CRSP switched the primarypermnoon2018-01-01.↩︎Only the last observation for a calendar year is kept by Jame et al. (2016) for CRSP and
yearmeansyear(datadate)for Compustat.↩︎