3 Regression fundamentals
In this chapter, we provide a short introduction to the fundamentals of regression analysis with a focus on ordinary least-squares (OLS) regression. Our emphasis here is on helping the reader to build intuition for the mechanics of regression. We demonstrate different ways of achieving various regression results to strengthen the reader’s intuition for what regression is doing. In this spirit, we close the chapter with a brief discussion of the Frisch-Waugh-Lovell theorem, which provides a way of representing multivariate regression coefficients as the result of a single-variable regression.
While we motivate some of our regressions with a data set that prompts a number of causal questions, we largely sidestep the issue of when OLS regression does or does not produce valid estimates of causal effects. Thus, while we hint at possible causal interpretations of results in this chapter, the reader should be cautious about these interpretations. We begin our formal analysis of causal inference with Chapter 4.
Additionally, while we note that OLS will provide noisy estimates of estimands, we do not address issues regarding how precise these estimates are or how to assess the statistical significance of results.1 A few p-values and t-statistics will crop up in regression analysis shown in this chapter, but we ignore those details for now. We begin our study of statistical inference in Chapter 5.
The code in this chapter uses the packages listed below. For instructions on how to set up your computer to use the code found in this book, see Section 1.2 (note that Step 4 is not required as we do not use WRDS data in this chapter). Quarto templates for the exercises below are available on GitHub.
3.1 Introduction
Suppose we have data on variables \(y\), \(x_1\) and \(x_2\) for \(n\) units and we conjecture that there is a linear relationship between these variables of the following form:
\[ y_i = \beta_0 + \beta_1 \times x_{i1} + \beta_2 \times x_{i2} + \epsilon_i \] where \(i \in {1, \dots, n}\) denotes the data for a particular unit. We can write that in matrix form as follows:
\[ \begin{bmatrix} y_1 \\ y_2 \\ \dots \\ y_{n-1} \\ y_{n} \\ \end{bmatrix} = \begin{bmatrix} 1 & x_{11} & x_{12} \\ 1 & x_{21} & x_{22} \\ \dots & \dots & \dots \\ 1 & x_{n-1,1} & x_{n-1, 2} \\ 1 & x_{n, 1} & x_{n, 2} \end{bmatrix} \times \begin{bmatrix} \beta_0 \\ \beta_1 \\ \beta_2 \end{bmatrix} + \begin{bmatrix} \epsilon_1 \\ \epsilon_2 \\ \dots \\ \epsilon_{n-1} \\ \epsilon_{n} \\ \end{bmatrix} \]
And this can be written even more compactly as:
\[ y = X \beta + \epsilon \] where \(X\) is an \(n \times 3\) matrix and \(y\) is an \(n\)-element vector. It is conventional to denote the number of columns in the \(X\) matrix using \(k\), where \(k = 3\) in this case.2
In a regression context, we call \(X\) the regressors, \(y\) the regressand, and \(\epsilon\) the error term. We assume that we observe \(X\) and \(y\), but not \(\epsilon\). If we did observe \(\epsilon\), then we could probably solve for the exact value of the coefficients \(\beta\) with just a few observations. Lacking such information, we can produce an estimate of our estimand, \(\beta\). Our estimate (\(\hat{\beta}\)) is likely to differ from \(\beta\) due to noise arising from the randomness of the unobserved \(\epsilon\) and also possibly bias. There will usually be a number of estimators that we might consider for a particular problem. We will focus on the ordinary least-squares regression (or OLS) estimator as the source for our estimates in this chapter.
OLS is a mainstay of empirical research in the social sciences in general and in financial accounting in particular. In matrix notation, the OLS estimator is given by
\[ \hat{\beta} = (X^{\mathsf{T}}X)^{-1}X^{\mathsf{T}}y \]
Let’s break this down. First, \(X^{\mathsf{T}}\) is the transpose of \(X\), meaning the \(k \times n\) matrix formed by making the rows of \(X\) into columns. Second, \(X^{\mathsf{T}} X\) is the product of the \(k \times n\) matrix \(X^{\mathsf{T}}\) and the \(n \times k\) matrix \(X\), which results in a \(k \times k\) matrix. Third, the \(-1\) exponent indicates the inverse matrix. For a real number \(x\), \(x^{-1}\) denotes the number that when multiplied by \(x\) gives \(1\) (i.e., \(x \times x^{-1} = 1\)). For a square matrix \(Z\) (here “square” means the number of rows equals the number of columns), \(Z^{-1}\) denotes the square matrix that when multiplied by \(Z\) gives the identity matrix, \(\mathbf{I}\) (i.e., \(Z \times Z^{-1} = \mathbf{I}\)).
The \(3 \times 3\) identity matrix looks like this
\[ \begin{bmatrix} 1 & 0 & 0 \\ 0 & 1 & 0 \\ 0 & 0 & 1 \end{bmatrix} \]
Note that, just as there is no meaningful way to calculate the inverse of \(0\), it’s not always possible to take the inverse of a matrix. But, so long as no column of \(X\) is a linear combination of other columns and \(n > k\), then we can calculate \((X^{\mathsf{T}}X)^{-1}\) (and there are standard algorithms for doing so). Now, \(X^{\mathsf{T}}y\) is the product of a \(k \times n\) matrix (\(X^{\mathsf{T}}\)) and a vector with \(n\) elements (this can be thought of as an \(n \times 1\) matrix), so the result will be a \(k \times 1\) matrix. Thus, the product of \((X^{\mathsf{T}}X)^{-1}\) and \(X^{\mathsf{T}}y\) will be a vector with \(k\) elements, which we can denote as follows:
\[ \begin{bmatrix} \hat{\beta}_1 \\ \hat{\beta}_2 \\ \hat{\beta}_3 \\ \end{bmatrix} \]
So \(X^{\mathsf{T}}X\) is a \(k \times k\) matrix (as is its inverse), and \(X^{\mathsf{T}}y\) is the product of a \(k \times N\) matrix times an \(N \times 1\) matrix (i.e., a vector). So \(\hat{\beta}\) is a \(k\)-element vector. If we have a single regressor \(x\), then \(X\) will typically include the constant term, so \(k = 2\).
For this chapter, we will assume that the model \(y = X \beta + \epsilon\) is a structural (causal) model. What this means is that if we could somehow increase the value of \(x_{i1}\) by 1 unit without changing any other part of the system, we would see an increase in the value of \(y_{i}\) equal to \(\beta_1\). This model is causal in the sense that a unit change in \(x_{i1}\) can be said to cause a \(\beta_1\) change in \(y_i\).
To make this more concrete, let’s consider some actual (though not “real”) data. The following code uses R functions to generate random data. Specifically, we generate 1000 observations with \(\beta = 1\) and \(\sigma = 0.2\). This is the first of at least a dozen simulation analyses that we will consider in the book.
To make our analysis easier to replicate, we include set.seed(2021) to set the random-number generator used by rnorm() to the same point, so that we can reproduce the analysis ourselves later and so that others can reproduce it too. For more on random-number generation, type ? set.seed in the R console. Note that the value 2021 is arbitrary and represents nothing more than the year in which this material was first written. Any value would work here, e.g., 2024, 42, or 20240215 could be used.
We next construct \(X\) as a matrix comprising a column of ones (to estimate the constant term) and a column containing \(x\).
[,1] [,2]
[1,] 1 -0.1224600
[2,] 1 0.5524566
[3,] 1 0.3486495
[4,] 1 0.3596322
[5,] 1 0.8980537
[6,] 1 -1.9225695Naturally, R has built-in matrix operations. To get \(X^{\mathsf{T}}\), the transpose of the matrix \(X\), we use t(X). To multiply two matrices, we use the matrix multiplication operator %*%. And to invert \((X^{\mathsf{T}}X)\) to get \((X^{\mathsf{T}}X)^{-1}\), we use the solve() function. Thus, the following calculates the OLS estimator \(\hat{\beta} = (X^{\mathsf{T}}X)^{-1} X^{\mathsf{T}}y\).
3.2 Running regressions in R
According to the documentation for lm():
The basic function for fitting ordinary multiple models is
lm(), and a streamlined version of the call is as follows:
fitted.model <- lm(formula, data = data.frame)For example,
fm1 <- lm(y ~ x1 + x2, data = production)would fit a multiple regression model of y on x1 and x2 using data from the data frame production. We use the lm() function—part of base R—to estimate regressions in this chapter.
Note that R was developed by statisticians and thus works in a way consistent with that history. For example, if we run the following code, we actually estimate coefficients on the constant term (the intercept), x1, x2, and the product of x1 and x2.
fm2 <- lm(y ~ x1 * x2, data = production)In contrast to other statistical packages, with lm() there’s no need to calculate the product of x1 and x2 and store it as a separate variable and there’s no need to explicitly specify the “main effect” terms (i.e., x1 and x2) in the regression equation. R (and the lm() function) takes care of these details for us. The third argument to lm() is subset, which allows us to specify as condition that each observation needs to satisfy to be included in the regression.
Here the first argument to lm() (formula) is “an object of class formula … a symbolic description of the model to be fitted.” As we are regressing \(y\) on \(x\), we use the formula y ~ x here; we will soon see more complicated formula expressions. The value to the data argument is normally a data frame, so below we put x and y into a tibble. We then call the lm() function, store the returned value in the variable fm, then show some of the contents of fm:
Call:
lm(formula = y ~ x, data = df)
Coefficients:
(Intercept) x
0.00754 0.99765 From this output, we see that we get the same results using lm() as we do using matrix algebra.
The data sets we will focus on next are test_scores and camp_attendance, both of which are part of the farr package. The test_scores data frame contains data on test scores for 1000 students over four years (grades 5 through 8).
test_scores# A tibble: 4,000 × 3
id grade score
<int> <int> <dbl>
1 1 5 498.
2 1 6 513.
3 1 7 521.
4 1 8 552.
5 2 5 480.
6 2 6 515.
# ℹ 3,994 more rowsThe camp_attendance data set contains data on whether a student attended a science camp during the summer after sixth grade.
camp_attendance# A tibble: 1,000 × 2
id camp
<int> <lgl>
1 1 TRUE
2 2 TRUE
3 3 FALSE
4 4 FALSE
5 5 FALSE
6 6 TRUE
# ℹ 994 more rowsWe can also see that exactly half the students in the sample attended the science camp.
camp_scores <-
test_scores |>
inner_join(camp_attendance, by = "id") |>
rename(treat = camp) |>
mutate(post = grade >= 7)The question we might be interested in is whether attending the science camp improves test performance. The natural first thing to do would be plot the data, which we do in Figure 3.1.
camp_scores |>
group_by(grade, treat) |>
summarize(score = mean(score),
.groups = "drop") |>
ggplot(aes(x = grade, y = score,
linetype = treat, colour = treat)) +
geom_line()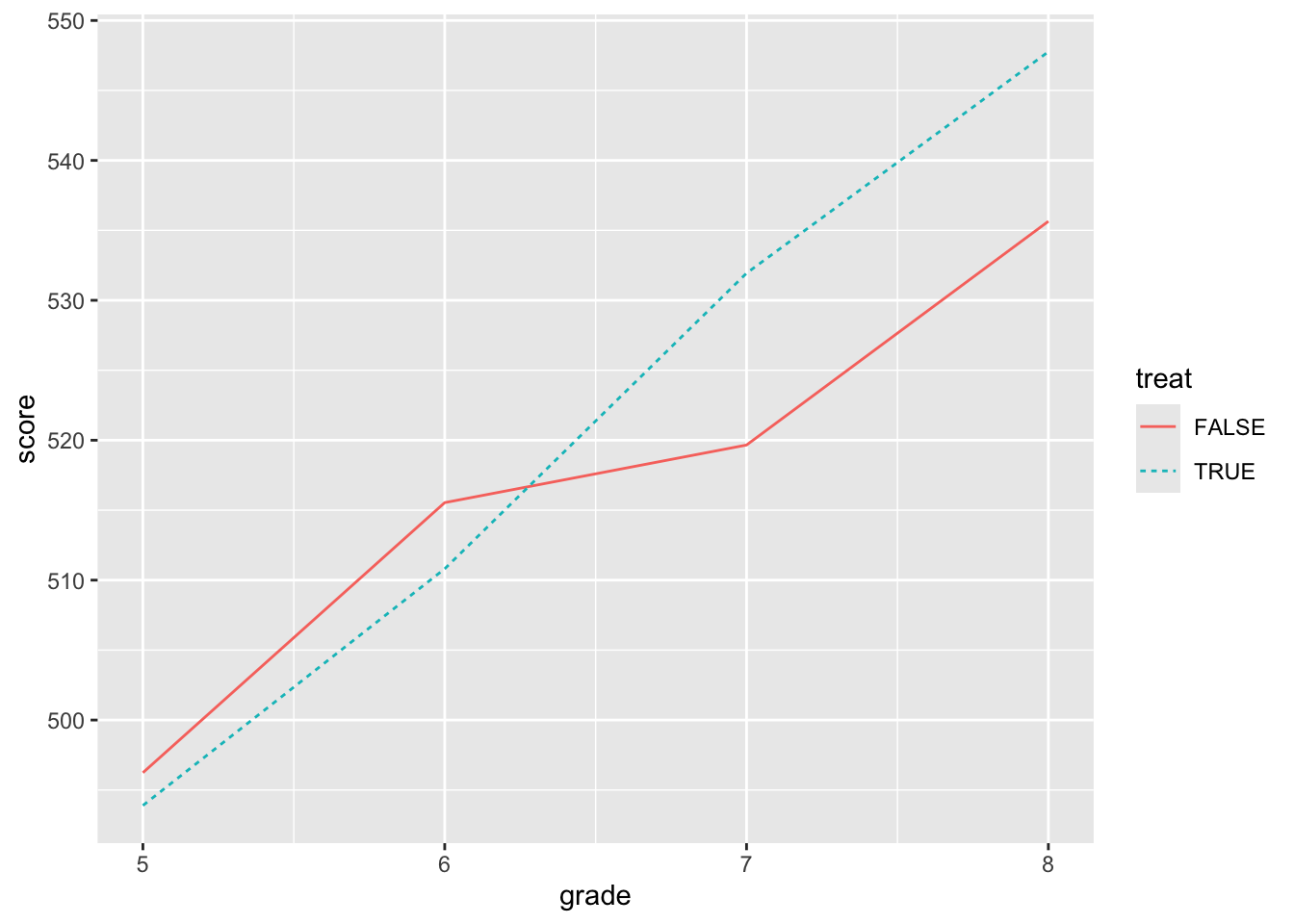
Figure 3.1 shows that the students who went to the camp had lower scores in grades 5 and 6 (i.e., before the camp), but stronger performance in grades 7 and 8. This provides prima facie evidence of a positive effect of the science camp on scores.
While the ideal approach might be to randomly assign students to the camp and then compare scores after the camp, in this case, it appears that students with lower scores went to camp. Given our lack of contextual information, there is no obvious story for what we see in Figure 3.1 that is more plausible than (or at least as simple as) one that attributes a positive effect on test scores of going to the science camp.
A question that we might now have is: What is the best way to test for an effect of the science camp on test scores? One reasonable hypothesis is that the summer camp has a biggest effect on seventh-grade scores and that we might compare seventh-grade scores with sixth-grade scores to get the best estimate of the effect of camp on scores.
In the code below, we use filter() to limit our analysis to data related to sixth and seventh grades. We then calculate mean scores for each value of (post, treat). We then use pivot_wider() to put score values for different levels of post in the same row so that we can calculate change.
You may find it helpful in understanding code examples such as this one to look at the intermediate output along the line of pipes. For example, if you highlight the text from test_scores |> through to the end of the summarize() line just before the pipe at the end of the last line, and click “Run Selected Lines” in the “Code” menu of RStudio (or hit CTRL + Enter on Windows or Linux or ⌘ + Enter on MacOS) you will see what is coming out at that point of the pipe (it should look like the following):
camp_scores |>
filter(grade %in% 6:7L) |>
mutate(post = grade >= 7) |>
group_by(post, treat) |>
summarize(score = mean(score), .groups = "drop")# A tibble: 4 × 3
post treat score
<lgl> <lgl> <dbl>
1 FALSE FALSE 516.
2 FALSE TRUE 511.
3 TRUE FALSE 520.
4 TRUE TRUE 532.We strongly recommend that you use this approach liberally when working through this book (and when debugging your own pipelines).
We stored the results of our analysis in test_summ, which we show in Table 3.1.
test_summ| treat | pre | post | change |
|---|---|---|---|
| FALSE | 515.539 | 519.657 | 4.118 |
| TRUE | 510.810 | 531.938 | 21.128 |
We see in Table 3.1 that the scores of the treated students (i.e., those who went to the summer camp) increased by 21.128, while the scores of the control students increased by 4.118. One approach is to view the outcome of the control students as the “but-for-treatment” outcome that the treated students would have seen had they not gone to summer camp. With this view, the effect of going to camp is the difference in the difference in scores, or 17.010. This is the difference-in-differences estimator of the causal effect.
We can also recover this estimator using the lm() function:
fm_dd <- lm(score ~ treat * post, data = camp_scores,
subset = grade %in% 6:7L)
coefficients(fm_dd) (Intercept) treatTRUE postTRUE treatTRUE:postTRUE
515.539023 -4.728960 4.118259 17.009708 Note that we did not need to specify the inclusion of the main effects of treat and post; R automatically added those when we requested their interaction (treat * post). Also note that we did not need to convert the logical variables treat and post so that TRUE is 1 and FALSE is 0; in effect, R also did this for us.
A natural question might be whether we could do better using all four years of data. There is no simple answer to this question unless we have a stronger view of the underlying causal model. One causal model might have it that students have variation in underlying talent, but that there is also variation in industriousness that affects how students improve over time. From the perspective of evaluating the effect of the camp, variation in industriousness is going to add noise to estimation that increases if we are comparing performance in fifth grade with that in eighth grade.
Another issue is that the effects of the summer camp might fade over time. As such, we might get a larger estimated effect if we focus on seventh-grade scores than if we focus on (or also include) eighth-grade scores. But from a policy perspective, we might care more about sustained performance improvement and actually prefer eighth-grade scores.
However, if we were willing to assume that, in fact, scores are a combination of underlying, time-invariant individual talent, the persistent effects (if any) of summer camp, and random noise, then we’d actually do better to include all observations.3
fm_dd_all <- lm(score ~ treat * post, data = camp_scores)
coefficients(fm_dd_all) (Intercept) treatTRUE postTRUE treatTRUE:postTRUE
505.887759 -3.536433 21.764629 15.735916 Another possibility is that scores are a combination of underlying, time-invariant individual talent, the persistent effects (if any) of summer camp, and random noise and the grade in which the test is taken. For example, perhaps the test taken in seventh grade is similar to that taken in sixth grade but, with an extra year of schooling, students might be expected to do better in the higher grade assuming the scores are not scaled in any way within grades. (Recall that we just have this data set without details that would allow us to rule out such ideas, so the safest thing to do is to examine the data.) The easiest way to include grade is as a linear trend, which means that grade is viewed as a number (e.g., 5 or 8):
fm_dd_trend <- lm(score ~ treat * post + grade, data = camp_scores)
coefficients(fm_dd_trend) (Intercept) treatTRUE postTRUE grade
412.335651 -3.536433 -12.254320 17.009474
treatTRUE:postTRUE
15.735916 Note that we have exactly the same coefficients on treat and treat * post as we had before (\(-3.5364\) and \(15.7359\), respectively). The easiest way to understand the estimated coefficients is to plug in some candidate \(X\) values to get the fitted values.
Suppose we have a student who went to summer camp. In grade 6, this student’s predicted score would be
\[ 412.3357 + -3.5364 + 6 \times 17.0095 = 510.8561 \]
In grade 7, this student’s predicted score would be
\[ 412.3357 + -3.5364 + 7 \times 17.0095 + 15.7359 = 543.6015 \]
An alternative approach that allows for grade to affect scores would be to estimate a separate intercept for each level that grade takes on. That is, we’d have a different intercept for grade==6, a different intercept for grade==7, and so on. While we could achieve this outcome by creating variables using an approach such as mutate(grade7 = grade == 7), it is easier to use the R’s support for factors.
As discussed in Chapter 2, factors are a type that is useful for representing categorical variables, which often have no meaningful numerical representation (e.g., “red” or “blue”, or “Australia” or “New Zealand”) or where we want to move away from a simple numerical representation (e.g., grade 7 may not be simply 7/6 times grade 6).4 Rather than adding a factor version of grade to the model above, let’s run a simpler regression.
fm_grade <- lm(score ~ factor(grade), data = test_scores)
coefficients(fm_grade) (Intercept) factor(grade)6 factor(grade)7 factor(grade)8
495.06454 18.11000 30.73311 46.64206 This model estimates fixed effects for each grade without other covariates. Table 3.2 provides the mean scores by grade for comparison.
| grade | score |
|---|---|
| 5 | 495.065 |
| 6 | 513.175 |
| 7 | 525.798 |
| 8 | 541.707 |
The idea of fixed effects is that there are time-invariant factors that have a constant effect on the outcome (hence fixed effects). In some settings, we would posit fixed effects at the level of the individual. Here we are positing fixed effects at the grade level. Working through the exercises should provide additional insights into what we are doing here. For more on fixed effects, see Cunningham (2021, pp. 391–392) and also Chapter 21.
Now, let’s estimate fixed effects for both grade and student (id). This will yield more fixed effects than we have students (we have 1000 students), so we suppress the coefficients for the fixed effect in the regression output, which is shown in Table 3.3.
fm_id <- lm(score ~ treat * post + factor(grade) + factor(id),
data = camp_scores, x = TRUE)
modelsummary(fm_id,
estimate = "{estimate}{stars}",
coef_omit = "^factor",
gof_map = "nobs",
stars = c('*' = .1, '**' = 0.05, '***' = .01))grade and id fixed effects
| (1) | |
|---|---|
| (Intercept) | 495.370*** |
| (2.527) | |
| treatTRUE | -2.235 |
| (3.570) | |
| postTRUE | 38.774*** |
| (0.276) | |
| treatTRUE × postTRUE | 15.736*** |
| (0.319) | |
| Num.Obs. | 4000 |
Note that we specified x = TRUE so that the \(X\) matrix used in estimation was returned by lm(). The size of this matrix is given by the dim() function:
dim(fm_id$x)[1] 4000 1006We have 1006 columns because we have added so many fixed effects. This means that \((X^{\mathsf{T}}X)^{-1}\) is a 1006 \(\times\) 1006 matrix. As we add more years and students, this matrix could quickly become quite large and inverting it would be computationally expensive (even more so for some other operations that would need even larger matrices). To get a hint as to a less computationally taxing approach, let’s see what happens when we “demean” the variables in a particular way.
Results from this analysis are shown in Table 3.4.
modelsummary(fm_demean,
estimate = "{estimate}{stars}",
coef_omit = "^factor",
gof_map = "nobs",
stars = c('*' = .1, '**' = 0.05, '***' = .01))| (1) | |
|---|---|
| (Intercept) | 3.934*** |
| (0.138) | |
| treatTRUE | -7.868*** |
| (0.195) | |
| postTRUE | -7.868*** |
| (0.195) | |
| treatTRUE × postTRUE | 15.736*** |
| (0.276) | |
| Num.Obs. | 4000 |
The size of the \(X\) matrix is now 4000 \(\times\) 4. This means that \((X^{\mathsf{T}}X)^{-1}\) is now a much more manageable 4 \(\times\) 4 matrix. While we had to demean the data, this is a relatively fast operation.
3.2.1 Exercises
In using
pivot_wider()in Chapter 2, we supplied a value to theid_colsargument, but we omitted that in creatingtest_summ. If we wanted to be explicit, what value would we need to provide for that argument in the code creatingtest_summ?What is the relation between the means in Table 3.2 and the regression coefficients in
fm_grade?Why is there no estimated coefficient for
factor(grade)5infm_grade?Now let’s return to our earlier regression specification, except this time we include fixed effects for
grade(see code below and output in Table 3.5). We now have two fixed effects omitted:factor(grade)5andfactor(grade)8. Why are we now losing two fixed effects, while above we lost just one? (Hint: Which variables can be expressed as linear combinations of thegradeindicators?)
modelsummary(fm_dd_fe,
estimate = "{estimate}{stars}",
gof_map = "nobs",
stars = c('*' = .1, '**' = 0.05, '***' = .01))grade fixed effects
| (1) | |
|---|---|
| (Intercept) | 496.833*** |
| (0.274) | |
| treatTRUE | -3.536*** |
| (0.316) | |
| postTRUE | 38.774*** |
| (0.388) | |
| factor(grade)6 | 18.110*** |
| (0.316) | |
| factor(grade)7 | -15.909*** |
| (0.316) | |
| treatTRUE × postTRUE | 15.736*** |
| (0.448) | |
| Num.Obs. | 4000 |
In words, what are we doing to create
camp_scores_demean? Intuitively, why might this affect the need to use fixed effects?Can you relate the coefficients from the regression stored in
fm_demeanto the numbers in Table 3.6? Which of these estimated coefficients is meaningful? All of them? Some of them? None of them?
grade and treat
| grade | treat | score |
|---|---|---|
| 5.0000 | False | 3.3377 |
| 5.0000 | True | -3.3377 |
| 6.0000 | False | 4.5302 |
| 6.0000 | True | -4.5302 |
| 7.0000 | False | -3.9746 |
| 7.0000 | True | 3.9746 |
| 8.0000 | False | -3.8933 |
| 8.0000 | True | 3.8933 |
- The
feols()function from thefixestpackage offers a succinct syntax for adding fixed effects and uses computationally efficient algorithms (much like our demeaning approach above) in estimating these. What is the same in the results below and the two specifications we estimated above? What is different? Why might these differences exist? What is theI()function doing here? What happens if we omit it (i.e., just includepost * treat)?
fefm <- feols(score ~ I(post * treat) | grade + id, data = camp_scores)
coefficients(fefm)I(post * treat)
15.73592 3.3 Frisch-Waugh-Lovell theorem
The Frisch-Waugh-Lovell theorem states that the following two regressions yield identical regression results in terms of both the estimate \(\hat{\beta_2}\) and residuals.
\[ y = X_1 \beta_1 + X_2 \beta_2 + \epsilon \] and
\[ M_{X_1} y = M_{X_1} X_2 \beta_2 + \eta \]
where \(M_{X_1}\) is the “residual maker” for \(X_1\) or \(I - P_{X_1} = I - X_1({X_1^{\mathsf{T}}X_1})^{-1}X_1^{\mathsf{T}}\), \(y\) is a \(n \times 1\) vector, and \(X_1\) and \(X_2\) are \((n \times k_1)\) and \((n \times k_2)\) matrices.
In other words, we have two procedures that we can use to estimate \(\hat{\beta}_2\) in the regression equation above. First, we could simply regress \(y\) on \(X_1\) and \(X_2\) to obtain estimate \(\hat{\beta}_2\). Second, we could take the following more elaborate approach:
- Regress \(X_2\) on \(X_1\) (and a constant term) and store the residuals (\(\epsilon_{X_1}\)).
- Regress \(y\) on \(X_1\) (and a constant term) and store the residuals (\(\epsilon_{y}\)).
- Regress \(\epsilon_{y}\) on \(\epsilon_{X_1}\) (and a constant term) to obtain estimate \(\hat{\beta}_2\).
The Frisch-Waugh-Lovell theorem tells us that only the portion of \(X_2\) that is orthogonal to \(X_1\) affects the estimate \(\hat{\beta}_2\). Note that the partition of \(X\) into \([X_1 X_2]\) is quite arbitrary, which means that we also get the same estimate \(\hat{\beta_1}\) from the first regression equation above and from estimating
\[ M_{X_2} y = M_{X_2} X_1 \beta_1 + \upsilon \]
To verify the Frisch-Waugh-Lovell theorem using some actual data, we draw on the data set comp from the farr package and a regression specification we will see in Chapter 24.
As our baseline, we run the following linear regression and store it in fm.
Here the dependent variable is ta (total accruals), big_n is an indicator variable for having a Big \(N\) auditor (see Section 25.1) and the other variables are various controls (use help(comp) or ? comp for descriptions of these variables). We again use the I() function we saw above and interact factor(fyear) with three different variables.
We then run two auxiliary regressions: one of ta on all regressors except cfo (we store this in fm_aux_ta) and one of cfo on all regressors except cfo (we store this in fm_aux_cfo). We then take the residuals from each of these regressions and put them in a data frame under the names of the original variables (ta and size respectively). Finally, using the data in aux_data, we regress ta on size.
fm_aux_ta <- lm(ta ~ big_n + size + lev + mtb +
factor(fyear) * (inv_at + I(d_sale - d_ar) + ppe),
data = comp, na.action = na.exclude)
fm_aux_cfo <- lm(cfo ~ big_n + size + lev + mtb +
factor(fyear) * (inv_at + I(d_sale - d_ar) + ppe),
data = comp, na.action = na.exclude)
aux_data <- tibble(ta = resid(fm_aux_ta),
cfo = resid(fm_aux_cfo))
fm_aux <- lm(ta ~ cfo, data = aux_data)The Frisch-Waugh-Lovell theorem tells us that the regression in fm_aux will produce exactly the same coefficient on cfo and the same residuals (and very similar standard errors) as the regression in fm, as can be seen in Table 3.7. Here we use modelsummary() from the modelsummary package to produce attractive regression output. We use coef_omit = "(fyear|ppe|inv_at|d_sale)" to focus on coefficients of greater interest.
modelsummary(list(fm, fm_aux),
estimate = "{estimate}{stars}",
coef_omit = "(fyear|ppe|inv_at|d_sale)",
gof_map = "nobs",
stars = c('*' = .1, '**' = 0.05, '***' = .01))| (1) | (2) | |
|---|---|---|
| (Intercept) | -0.017 | 0.000 |
| (0.028) | (0.004) | |
| big_nTRUE | 0.022* | |
| (0.011) | ||
| cfo | 0.141*** | 0.141*** |
| (0.008) | (0.008) | |
| size | 0.000 | |
| (0.002) | ||
| lev | -0.066*** | |
| (0.013) | ||
| mtb | 0.000*** | |
| (0.000) | ||
| Num.Obs. | 8850 | 8850 |
The Frisch-Waugh-Lovell theorem is an important result for applied researchers to understand, as it provides insights into how multivariate regression works. A side-benefit of the result is that it allows us to reduce the relation between two variables in a multivariate regression to a bivariate regression without altering that relation. For example, to understand the relation between cfo and ta embedded in the estimated model in fm, we can plot the data.
We produce two plots. The first—Figure 3.2—includes all data, along with a line of best fit and a smoothed curve of best fit. However, Figure 3.2 reveals extreme observations of the kind that we will study more closely in Chapter 24 (abnormal accruals more than 5 or less than 5 times lagged total assets!).
So we trim the values of ta at \(-1\) and \(+1\) and produce a second plot.5 In Figure 3.3, there is no visually discernible relation between size and ta and the line of best fit is radically different from the curve. If nothing else, hopefully these plots raise questions about the merits of blindly accepting regression results with the messy data that we often encounter in practice.
aux_data |>
filter(!is.na(cfo), !is.na(ta)) |>
ggplot(aes(x = cfo, y = ta)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ x, se = FALSE, linetype = 2,
colour = "red") +
geom_smooth(method = "gam", formula = y ~ s(x, bs = "cs"), se = FALSE)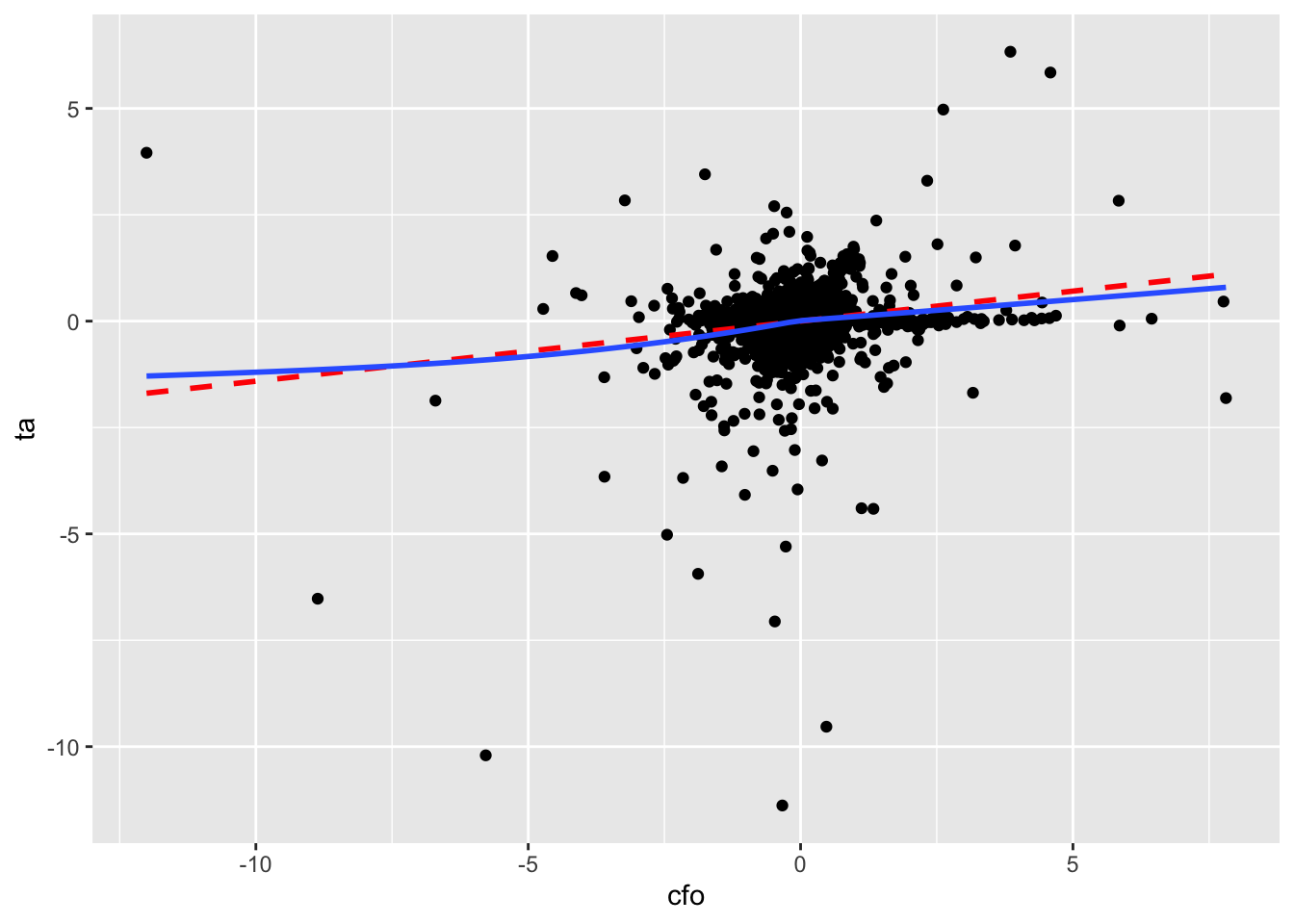
aux_data |>
filter(!is.na(cfo), !is.na(ta), abs(ta) < 1) |>
ggplot(aes(x = cfo, y = ta)) +
geom_point() +
geom_smooth(method = "lm", formula = y ~ x, se = FALSE, linetype = 2,
colour = "red") +
geom_smooth(method = "gam", formula = y ~ s(x, bs = "cs"), se = FALSE)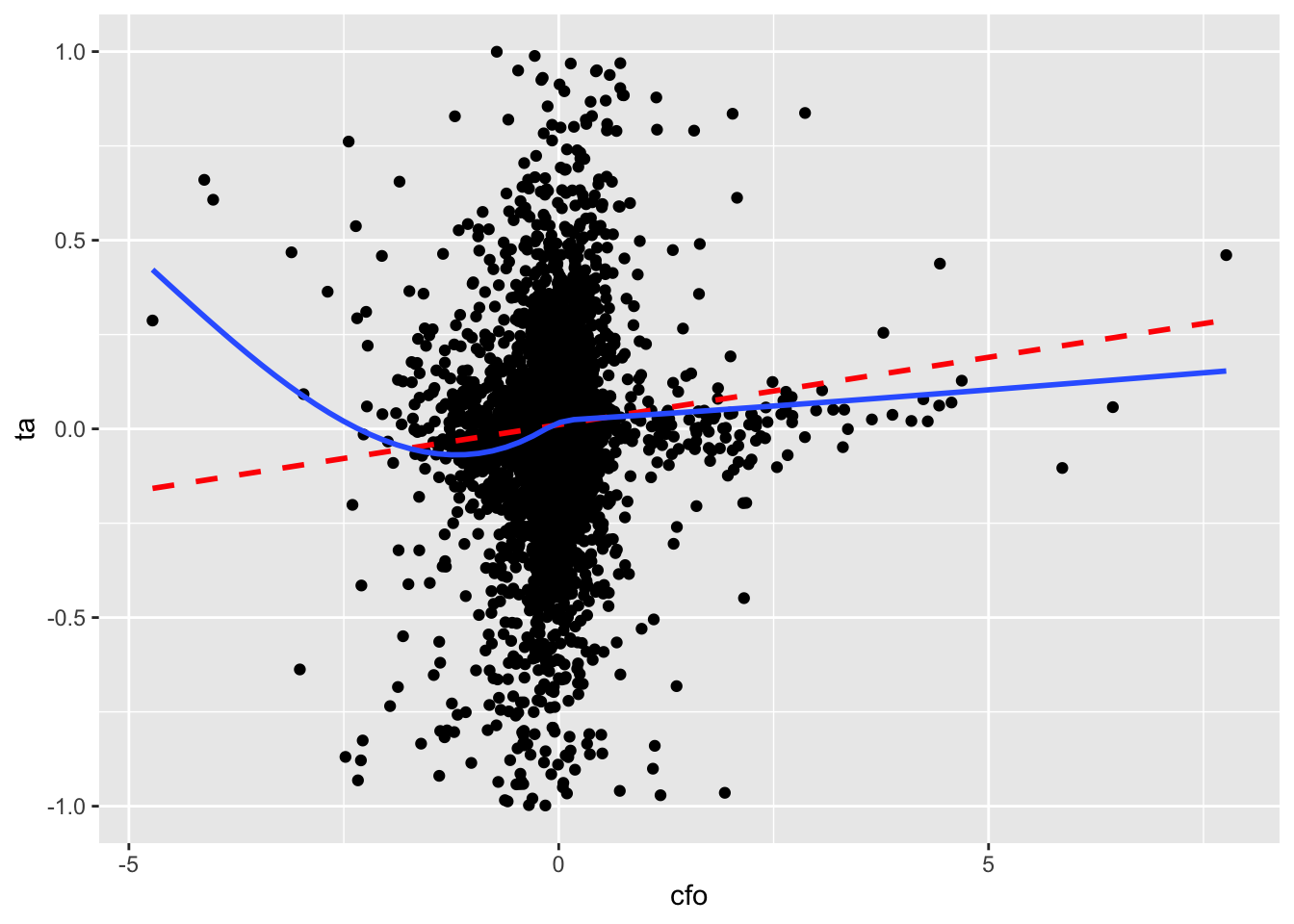
3.3.1 Exercises
Verify the Frisch-Waugh-Lovell theorem using
big_nandlevin place ofcfoand produce plots like Figure 3.2 for each variable. Does the plot withbig_nas the independent variable seem less helpful?Above we said that the standard errors of the main regression and the auxiliary regression using the Frisch-Waugh-Lovell theorem should be “very similar”. Confirm that the standard errors are similar across the variants of
fmandfm_auxthat you calculated for the previous question. (Hint:summary(fm_aux)$coefficientsandsummary(fm)$coefficients["big_nTRUE", ]should provide access to the data you want to compare.) Can you guess what might explain any differences? (Hint: Comparefm$df.residualandfm_aux$df.residualand perhaps usesqrt().)In words, what effect does converting
fyearinto a factor and interacting it withinv_at,I(d_sale - d_ar)andppehave? (Hint: It may be helpful to visually inspect the more complete regression output produced withoutcoef_omit = "(fyear|ppe|inv_at|d_sale)".)
3.4 Further reading
This chapter provides a bare minimum introduction to running regressions in R plus some concepts that help develop intuition about what’s going on in OLS regression. Treatments that provide a similar emphasis on intuition, but go deeper into the details include Angrist and Pischke (2008) and Cunningham (2021). Any econometrics textbook will offer a more rigorous treatment of OLS and its properties.
An estimand is simply a fancy way of saying the thing we’re trying to estimate.↩︎
For a quick overview of some details of matrix algebra, see Appendix A.↩︎
The idea here being that more data is better than less. This idea will show up again in later chapters.↩︎
R for Data Science has a whole chapter devoted to factors: https://r4ds.hadley.nz/factors.html.↩︎
That is, values less than \(-1\) are set to \(-1\) and values greater than \(+1\) are set to \(+1\). This is similar to winsorization, which we discuss in Chapter 24.↩︎